Decoder-only Transformer model
Understanding Large Language models with GPT-1
Over past 6 months, everywhere around the internet — ChatGPT was the term buzzing around and it is in fact acknowledged that the next-decade will be the decade of generative models.
There are many Generative models like Autoregressive models, Variational autoencoders, Normalizing flow models, Generative adversarial networks, etc..
ChatGPT could be considered as one of the deep-generative model’s language processing application. GAN(Generative adversarial networks)’s DeepFake is one of the deep-generative model’s computer vision application. Generative models is an exciting and rapidly-evolving fields of statistical machine learning and artificial intelligence.
Dive into language based Generative models
ChatGPT was primarily built upon an improved version of OpenAI’s GPT-3 model known as GPT-3.5
What is meant by GPT?
The first paper from OpenAI on the GPT models is called Improving Language Understanding by Generative Pre-Training. Thus, the term GPT has been derived from Generative Pre-Training.
GPT-1 model at the core is Decoder part of Transformer model. So, to understand GPT-1 model (or) any GPT models, it is necessary to understand Transformer model.
In the research paper, Generative pre-training is described as — the ability to train language models with unlabeled data and achieve accurate prediction.
At the end of this article, let’s revisit Generative pre-training and make it clear.
In the Transformer’s blog, I clearly explained about Decoder part. The Decoder block of GPT-1 model is no different from the Decoder block of Transformer, expect a nuances in the multi-head attention layers in a the decoder block. So, I would try to provide a high-level overview of the architecture of GPT-1 model.
Architectural view of GPT-1 model
It is always important to understand the input and output to any model, before diving into the architecture of the model. Let’s understand the input and output to the Decoder-only transformer in chatGPT way.
The input is fed into the transformer model at a time (without recurrent structure).
**Input : This blog helps you in understanding — Assume, this as the prompt given to the model.
The output depends on the objective of the model. If the model is designed for question-answering or next word prediction, next sentence prediction, etc. Typically, for GPT models — the output is the probability distribution of the next token/word that comes after the prompt. It outputs one prediction for the complete input.
Output : This blog helps you in understanding GPT
So, the word GPT is being predicted by the model. The prompt could have filled with any words like Attention, Backpropagation, etc.. but the model chosen only GPT because the probability of the word GPT to occur after the prompt is higher compared to remaining words.
How does the model justify that the word GPT being correct by leaving other words? — because, the model has learnt the attention to be more on word GPT using self-attention mechanism — which is detailed in the Transformers blog.
**The input to the Decoder network is positional encoded vector, which is derived from the word embedding vector of the input sentence/word.


There would be 12 Decoder blocks in the entire network. Each Decoder block consists of masked multi-head attention layer followed by Normalization layer and feed-forward neural network followed by Normalization layer. The output of this Decoder block will be input to the next Decoder block.

Finally, at the end of 12th Decoder block, the output is connected to the linear feed-forward layer and then to the softmax layer to generate the output.
What is Masked Self-Attention?
In the decoder-only transformer, masked self-attention is like sequence padding. In the Encoder-Decoder Transformer model, the Encoder could see the whole original language sentence (we took telugu sentence in the encoder network) but, the Decoder could only see the part of the sentence which was already translated, the left-over part of the sentence is termed as masking.
For example:
Input : [‘This’] Masked_value : [‘blog’, ‘helps’, ‘you’, ‘ in’, ‘ understanding’]
Input : [‘This’, ‘blog’] Masked_value : [‘helps’, ‘you’, ‘ in’, ‘ understanding’]
In this way, the masking of words would be done. All the other concepts such as Multi-head attention and Positional embeddings have already been discussed in-detail in the Transformers blog.
How does the Training happen?
The BASIC training process of GPT models consists of self-supervised learning mechanism. In simple words, a lot of text is gathered — strip the last word from the gathered text and then feed it as input to the transformer model, now check whether the output prediction matches the word that is stripped earlier — then backpropagate the error (It’s actually complex behind the scenes, that is reason behind millions of parameters training happens in the backend for transformer models).
Let’s consider an example : I am learning data science.
Input : [‘I’] Expected_output : [‘am’]
Input : [‘I’, ‘am’] Expected_output : [‘learning’]
Input : [‘I’, ‘am’, ‘learning’] Expected_output : [‘data’]
Input : [‘I’, ‘am’, ‘learning’, ‘data’] Expected_output : [‘science’]
Actually, when sending an Input —padding is added until maximum sentence/sequence length.
Fine-tuning / transfer-learning
After the training of the model is completed, the model is now a LARGE-LANGUAGE MODEL because, it can predict the next word based on a context.
If the business requirement is to work on specific type of the data, then through the process of fine-tuning or transfer-learning the model can be adapted to better suit the needs of the business problem.
The reason behind the GPT models (GPT-2, GPT-3, GPT-3.5) perform better than other Transformer models is because of the second stage of training.
In this second stage of training —
- The model is given a prompt and generates different answers.
- These answers are ranked by the human (rating it from best to worst).
- These scores are then backpropagated.
Other than language generation, Transformer models can also be used for tasks like sentiment analysis.
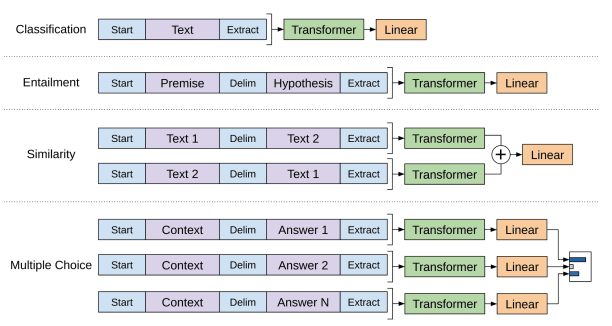
These transformer model can be fine-tuned for different types of tasks. For instance, The sentiment analysis task could be performed by removing the linear layer and replacing it with a different layer suitable for the task to be executed. We convert all structured inputs into token sequences to be processed by our pre-trained model, followed by a linear+softmax layer
Inference
Inference with a transformer is like training. A prompt is given, the model responds with the next word corresponding to that prompt — if it is a language generation (next-word prediction task).
It is important to understand that — for any GPT model, the prompt is extended one word at a time which means —
- When a prompt is given, the model gives the next corresponding word to that prompt as an output.
- This output is added to the prompt, creating as a new prompt again.
- This new prompt is forwarded through the model, then the model again gives the prediction of a new word.
Actually, the output is the probability for each word/token to be the next one.
Limitations and fine-tuning can be solution
GPT models are already trained on huge dataset volumes (millions of data records). So, when the prompt is given, the Transformer/GPT model can give the output because the model has already seen similar sentences during it’s training (There is NO on-the-go training happening).
The GPT model (or) Transformers can sometimes provide with a very different output than expected — this happens, when the input (prompt) is very different from the data, the model trained on. (for example: Healthcare data) — it is when the fine-tuning is required.

This story is published on Generative AI. Connect with us on LinkedIn and follow Zeniteq to stay in the loop with the latest AI stories.
Subscribe to our newsletter and YouTube channel to stay updated with the latest news and updates on generative AI. Let’s shape the future of AI together!


