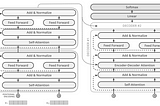
InArtificial Intelligence in Plain EnglishbyChamanth mvsDetailed explanation about Attention mechanismSequence-Sequence model with Attention mechanismMay 27, 2023May 27, 2023
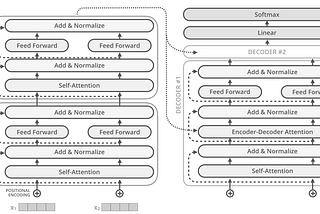
InDataDrivenInvestorbyChamanth mvsSelf-Attention is not typical Attention modelUnderstanding Transformer modelJun 12, 20233Jun 12, 20233
InDataDrivenInvestorbyChamanth mvsDetailed view of BERTExploring Large Language models with underlying conceptsJun 28, 2023Jun 28, 2023
InDataDrivenInvestorbyChamanth mvsA step into Zero-Shot LearningA conceptual understanding of Zero shot learningJul 29, 2023Jul 29, 2023
InGenerative AIbyChamanth mvsA brief on GPT-2 and GPT-3 modelsSummarizing OpenAI ’s GPT-2 and GPT-3 modelsJul 30, 2023Jul 30, 2023
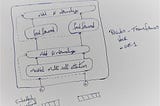
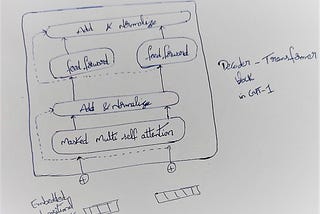
InGenerative AIbyChamanth mvsDecoder-only Transformer modelUnderstanding Large Language models with GPT-1Jun 18, 20233Jun 18, 20233
InArtificial Intelligence in Plain EnglishbyChamanth mvsUnderstanding of GANOne of the popular generative modelsMar 29, 2023Mar 29, 2023